The trust layer for AI on your enterprise data.
A live context layer, compiled from your code, that checks every AI answer and every change before it ships.
The Data Context Layer
A semantic ontology of every definition, pipeline, dashboard, and system across your data platform, compiled from your code, always current, always traceable.
Rigorously tested on real-world data workflows. Context changes everything.
Agents with full lineage context dramatically outperform those without it.
Data Context Layer
Data Context Layer
Task Success Rate (TSR) measures the percentage of real-world data engineering tasks completed successfully against production-grade acceptance criteria. Tested across impact analysis, root cause debugging, and model refactoring.
What agents do with a real context layer.
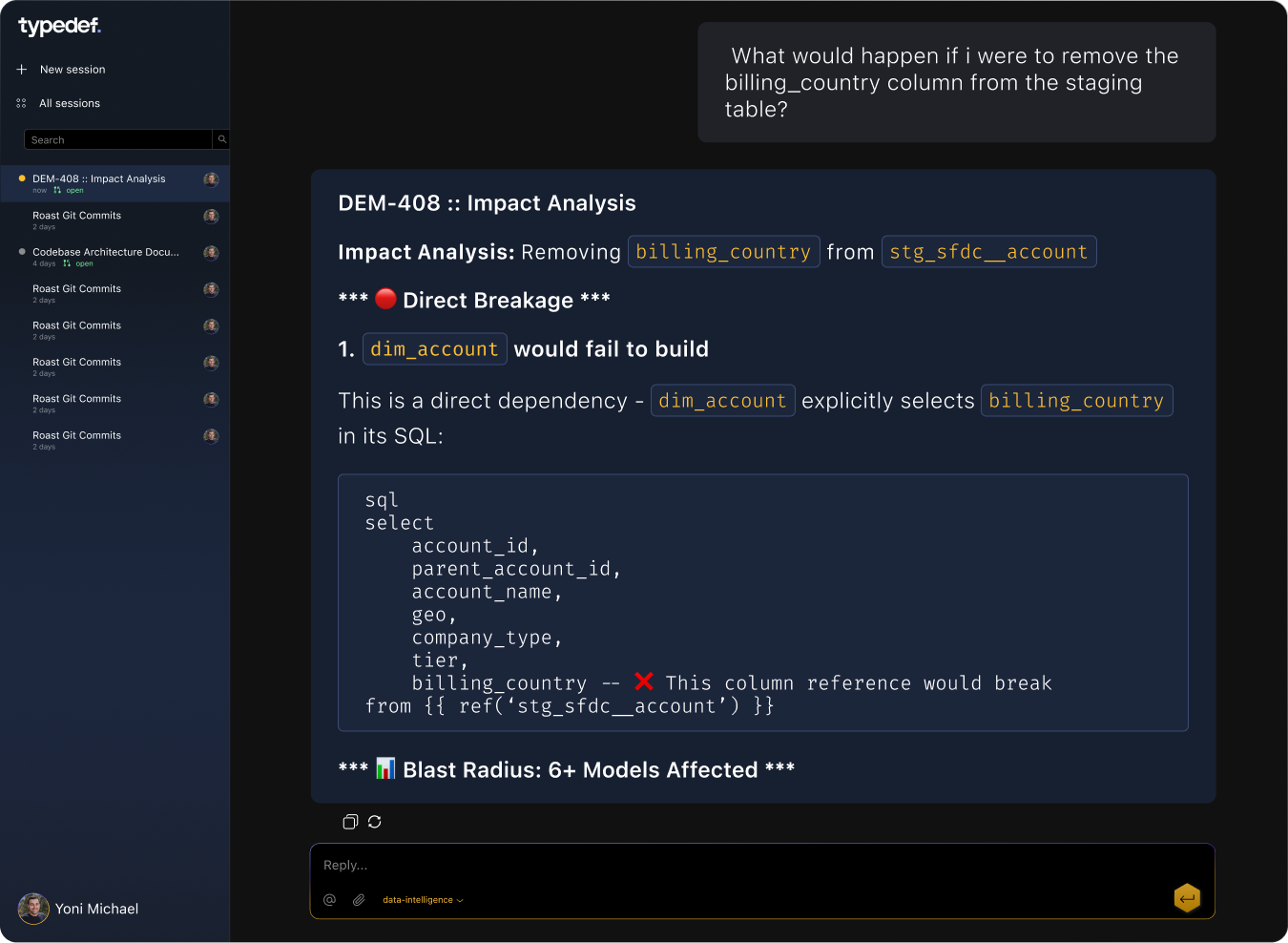
Blast radius before you merge
Change a staging model and see every downstream report, metric, and dashboard affected before the PR lands.
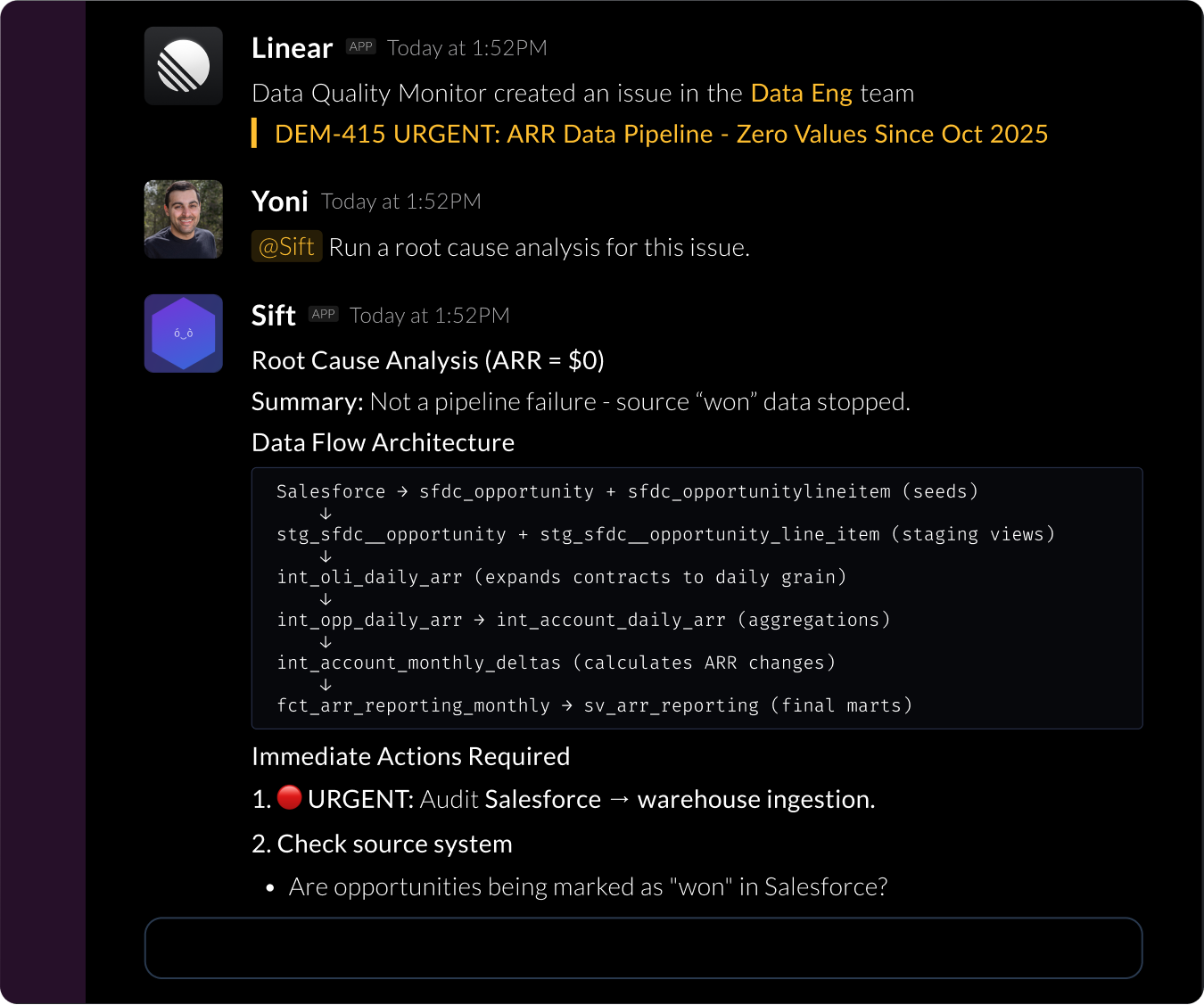
Root cause in minutes
When a pipeline breaks, Typedef traces lineage to the failing node and the upstream change that caused it.
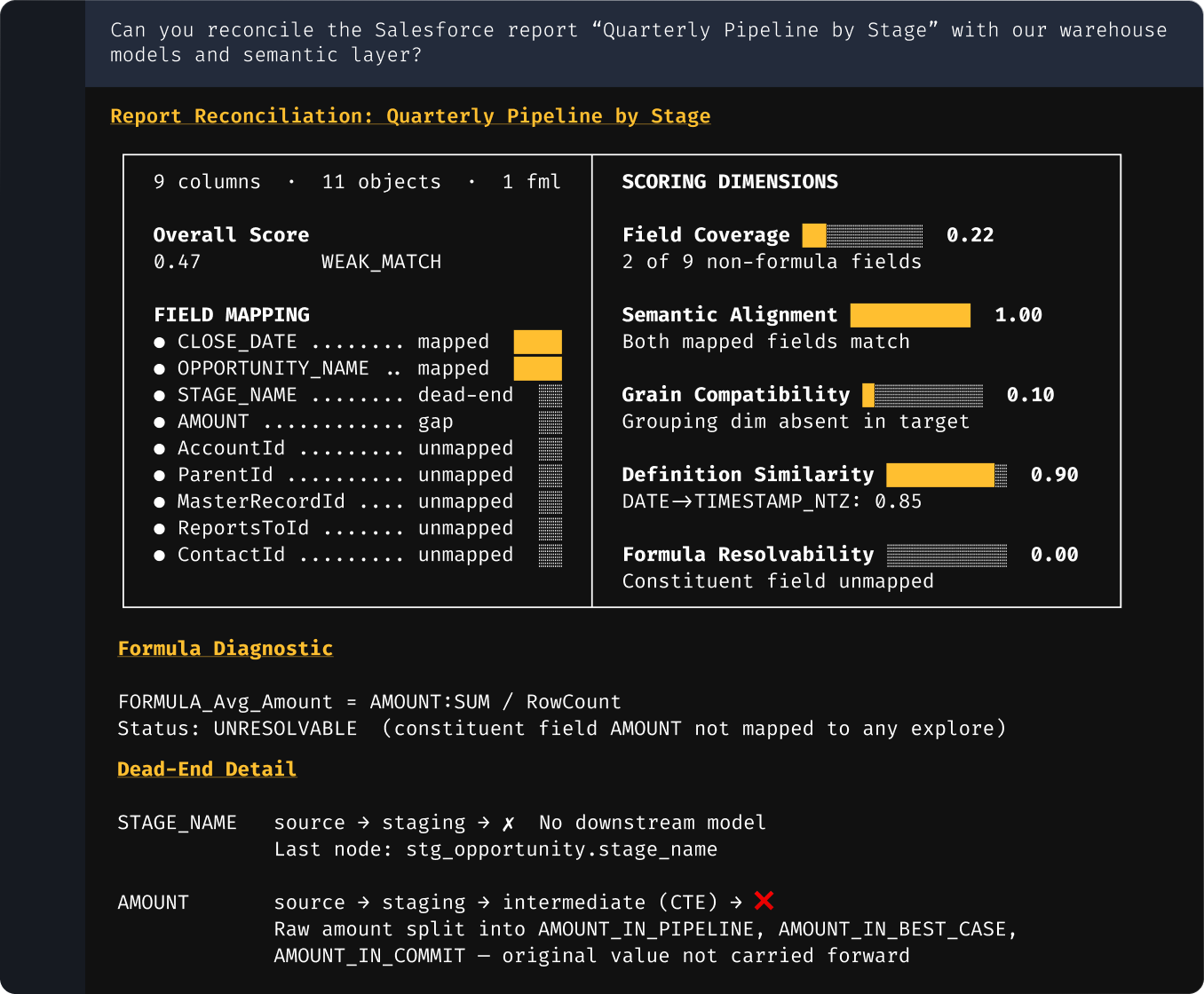
Metric reconciliation
Trace every field from source report to BI layer and see exactly where two systems' numbers diverge, and which to trust.
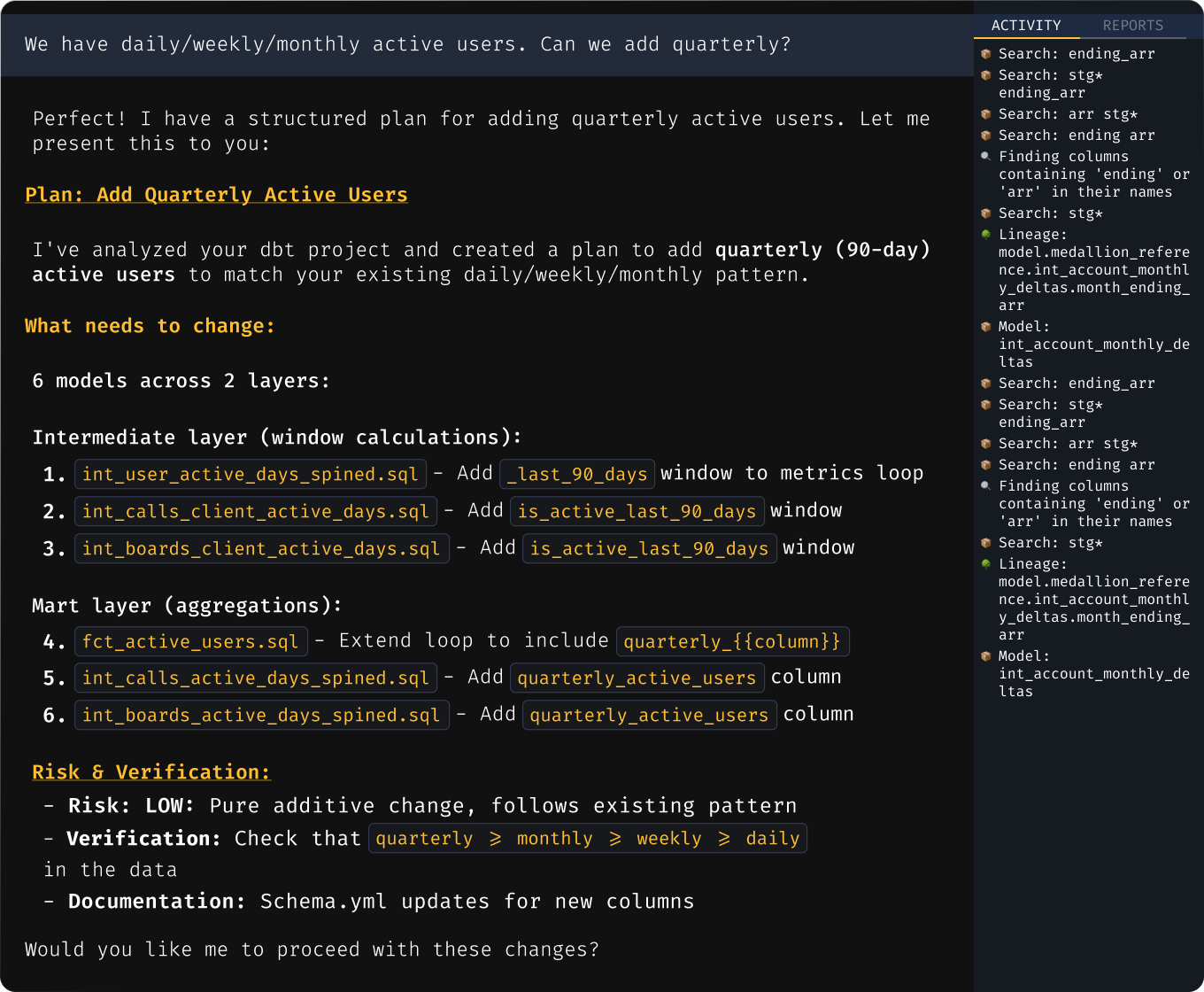
Safe change plans
Get an implementation plan for each layer with verification steps and risk analysis, grounded in real lineage.
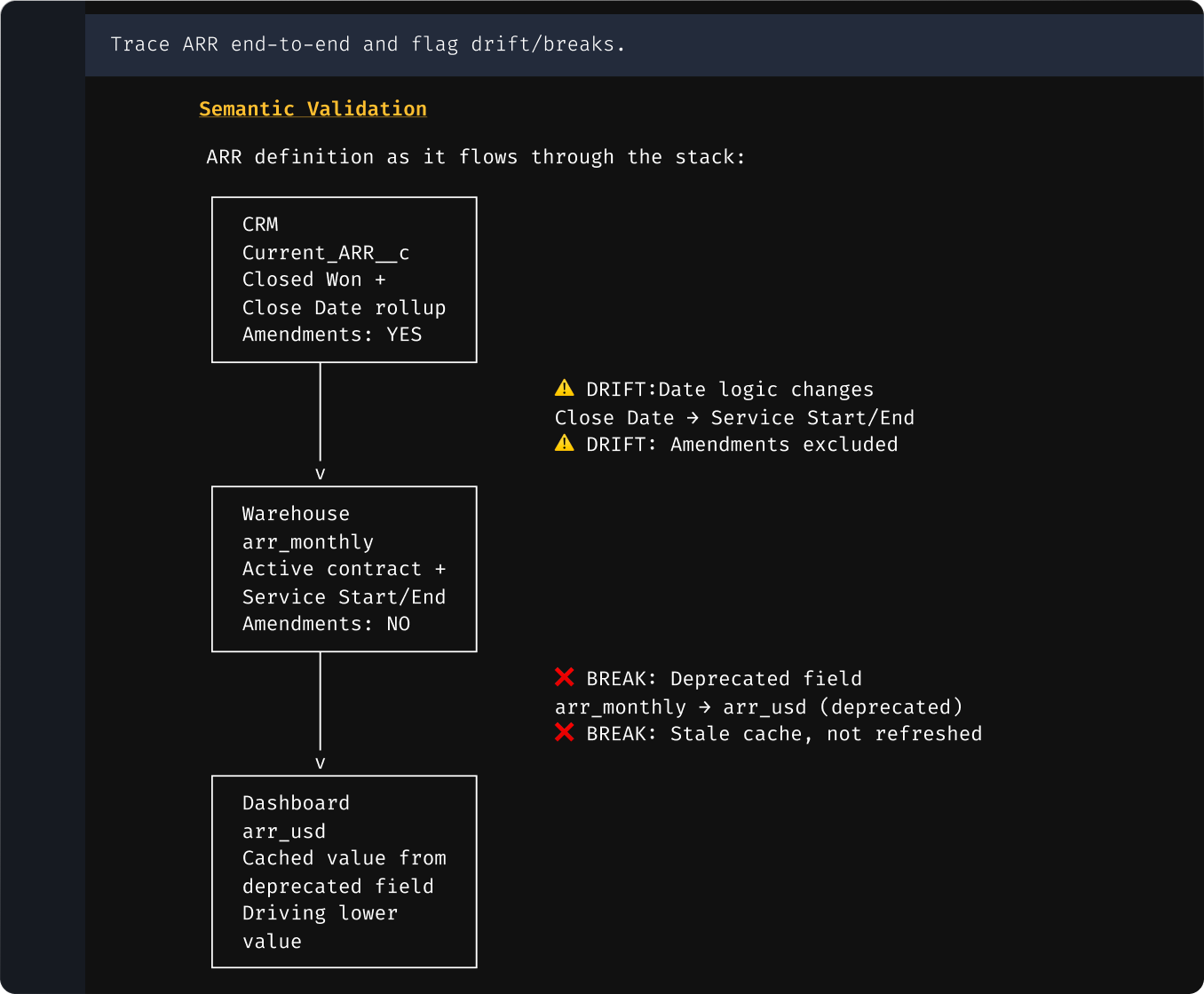
Certified metrics
Compare how a metric is computed across every model that defines it, from filters and grain to date logic and aggregation, and catch the ones that aren't safe to sum.
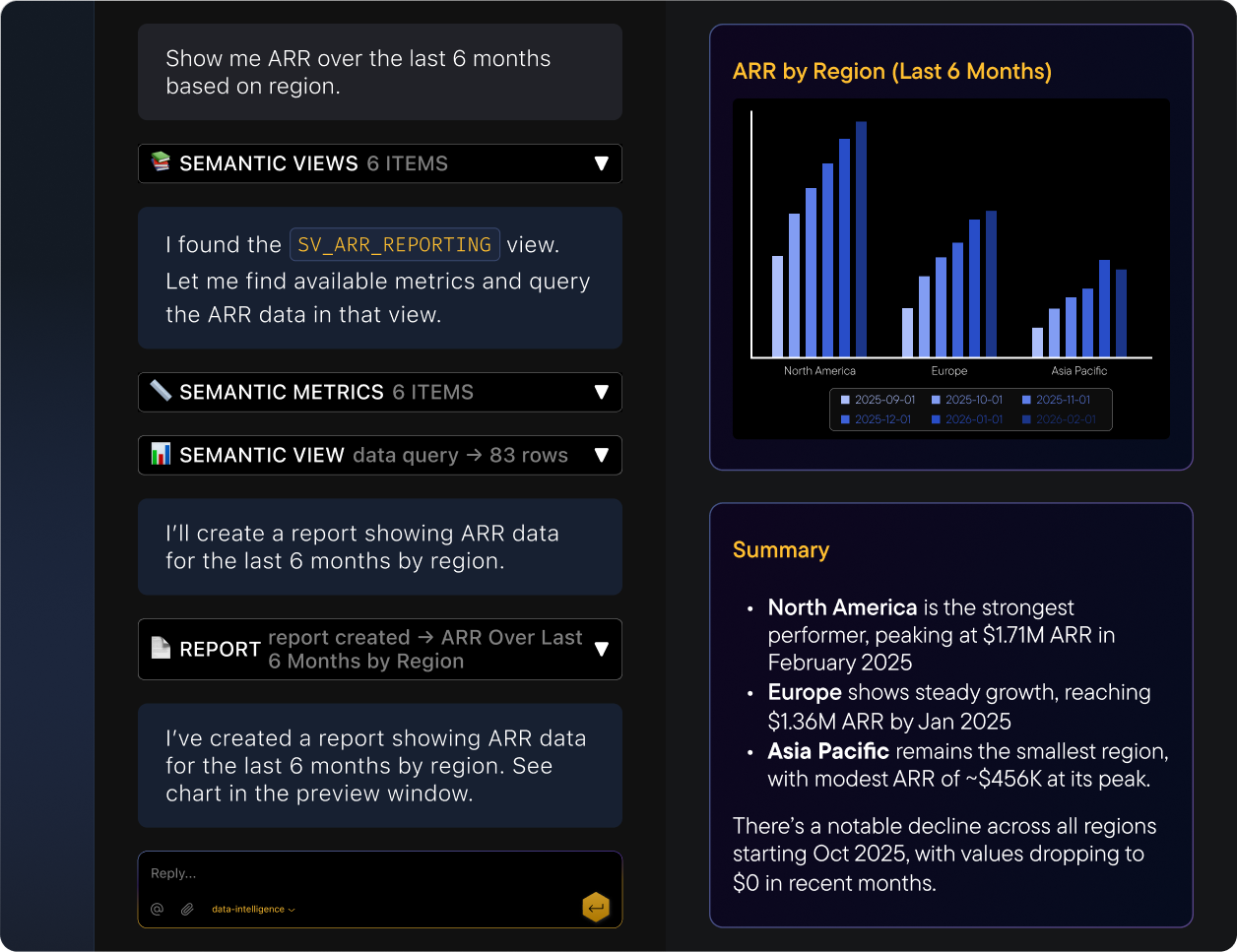
Trustworthy agentic analytics
Back every BI agent with a shared, always current model of your stack, so answers are explainable, not guessed.
Enterprise-Grade Security
SOC 2 Type II + GDPR
Compliance-aligned controls, logging, and auditability built in.
VPC Deployment
Deployed into your private VPC with your network and key controls.
Secure Encryption
Typedef leverages SSO, RBAC, and full audit trails by default.
No Data Egress
Runs entirely inside your environment.