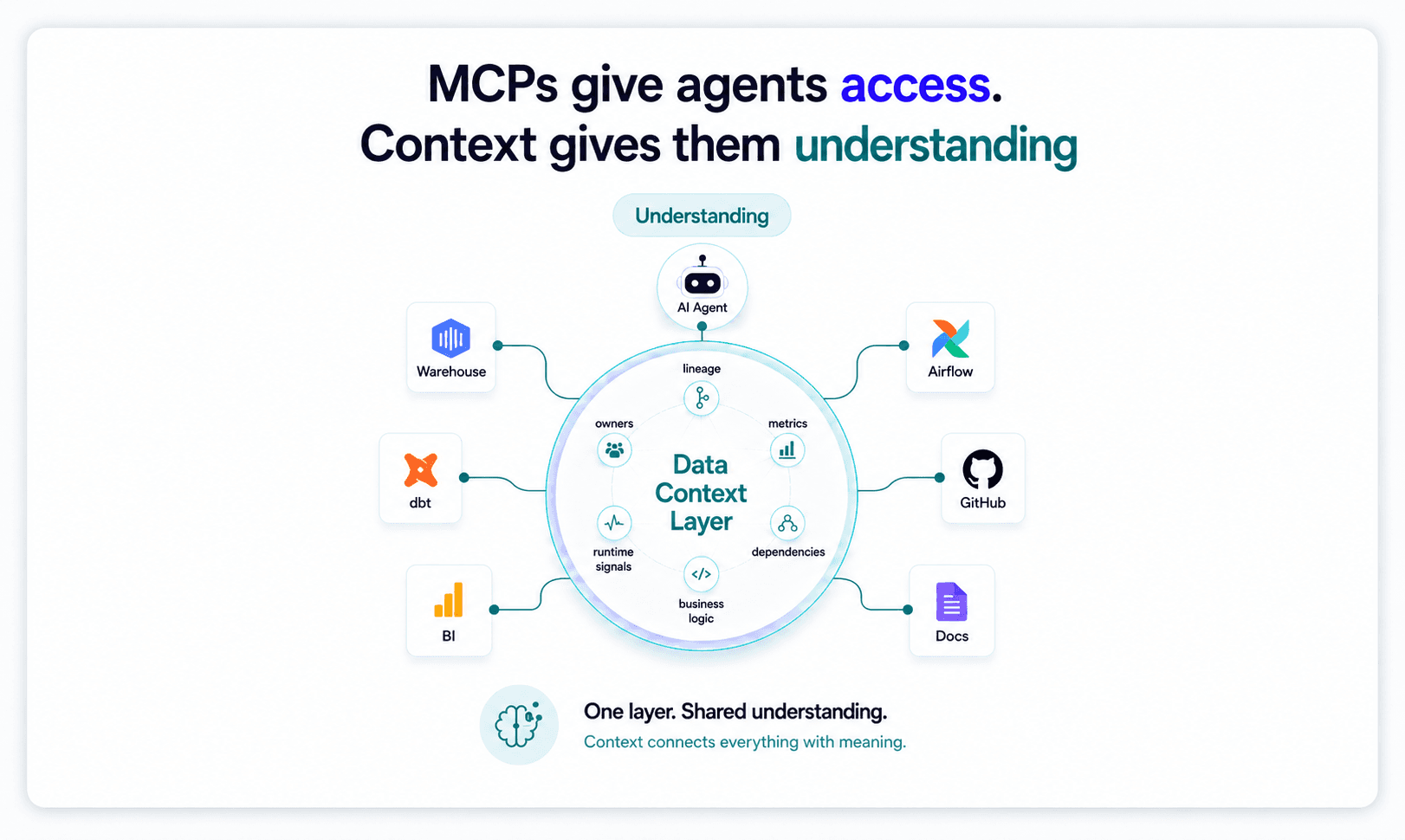
MCPs have quickly become an important part of the agentic software stack. They give AI agents a standard way to interact with tools and systems, which is especially useful for data teams working across Snowflake, BigQuery, Databricks, dbt, Looker, Airflow, GitHub, Linear, and the rest of the modern data stack.
That is a meaningful step forward. Agents are far more useful when they can inspect systems, run queries, read project files, search dashboards, open tickets, and trigger workflows.
But there is a distinction that matters a lot for production data work: just because an agent can access a system does not mean it understands the system.
MCPs are great at exposing tools. They are not, by themselves, a substitute for the institutional context that data teams rely on every day.
Access is not context
Many agent demos work because the task is narrow. If you ask an agent to show you the schema for a table, run a query, open a dbt model, or find a dashboard that references a field, MCPs can be extremely helpful. They give the agent a clean interface for retrieving information or taking action.
The harder data engineering questions, however, are usually not just access problems. They are context problems.
For example, consider questions like these:
- Can I change this dbt model without breaking downstream dashboards?
- Why did this metric move last week?
- Which definition of revenue is the right one for this analysis?
- What pipelines are affected if we migrate this source?
- Why is this dashboard wrong even though the SQL looks fine?
- Which team owns the business logic behind this field?
- Is this failure caused by upstream data, transformation logic, orchestration, or BI semantics?
An agent with a dbt MCP can inspect models, an agent with a Snowflake MCP can query the warehouse, an agent with a Looker MCP can find dashboards, and an agent with an Airflow MCP can inspect DAGs.
Those interfaces are very useful, but none of them individually tells the agent how the full data system works. They do not tell the agent which models are trusted, where the business logic lives, which joins are safe, which dashboards executives rely on, which metric definition is canonical, what changed recently, or what tribal knowledge the data team has built up over years.
That context usually lives across code, warehouse metadata, BI tools, orchestration systems, docs, Slack threads, tickets, incident notes, query history, and people’s heads. MCPs expose those systems, but they do not automatically unify the meaning across them.
The rediscovery problem
When an agent does not have persistent context, every session starts from a cold start. The agent has to rediscover the same details again and again: what a model does, what its grain is, who consumes it, which dashboards depend on it, which upstream sources feed it, which tests matter, which columns are semantically important, and which definitions are stale or trusted.
That may be acceptable for small tasks, but it breaks down quickly for production data workflows.
A senior analytics engineer does not operate from a cold start every time they review a change. When they look at a dbt model, they are not only reading the SQL in front of them. They bring accumulated knowledge about how the marts are structured, which dashboards are fragile, which models are overloaded, which teams depend on certain definitions, and where strange historical decisions are buried.
That is why an experienced data engineer can look at a small SQL change and know that it may break finance reporting, alter the grain of a downstream dataset, or invalidate a dashboard used by an executive team.
That judgment comes from institutional knowledge, not just from database access alone.
If agents are going to do meaningful data work, they need a machine-usable version of that institutional knowledge as well.
Why data work is uniquely context-heavy
Data systems are different from ordinary codebases in ways that make context especially important. In software engineering, compilers, tests, types, and runtime boundaries provide a lot of structure. Developers can often reason locally about a function, module, or service.
Data systems on the other hand, are much messier. A small change in a staging model can silently alter a metric three layers downstream. A join that looks correct can change the grain of a dataset. A dashboard can depend on a field through a BI semantic model rather than through a direct SQL reference. A source table can be technically fresh but semantically wrong. Two teams can use the same metric name to mean different things. A field can be deprecated in code while still being used in executive reporting.
The dependencies are broad, the semantics are often implicit, and the correctness criteria are frequently defined by business meaning rather than purely technical rules.
This is where generic agents struggle. They can call tools, inspect files, generate SQL, and summarize documentation. But when the task requires understanding how code, data, orchestration, metrics, and business logic connect across systems, tool access alone is not enough.
MCPs are necessary, but not sufficient
To be clear, MCPs are a major step forward. They give agents a cleaner way to interact with enterprise systems, reduce bespoke integration work, and make it easier for agents to take useful actions across the stack.
But MCPs should be understood as the access layer, not the understanding layer.
A useful mental model is that MCPs give agents hands, while the context layer gives them memory. The hands let the agent act, but the memory tells the agent what matters.
For data teams, that memory needs to be persistent, structured, and continuously updated. It needs to represent the relationships between dbt models, warehouse tables, source systems, orchestration jobs, BI dashboards, metrics, semantic definitions, lineage, test failures, runtime signals, ownership, usage patterns, and business logic.
That is the difference between an agent that can answer “what tables does this query use?” and an agent that can answer “can I safely change this model?”
It is the difference between an agent that can generate SQL and an agent that can verify whether the answer is using the right definition, at the right grain, from the right source.
It is the difference between an agent that can open a failing DAG and an agent that can explain the likely root cause, downstream impact, and safest fix.
What a Data Context Layer gives agents
At Typedef, we believe the missing primitive for production data agents is a Data Context Layer: a persistent, continuously updated understanding of the data stack that agents can reason over.
A Data Context Layer is not just a catalog, a semantic layer, a vector index over documentation, or a collection of MCP servers. It is a living representation of how the data system works.
That representation needs to include the technical structure of the system, such as models, tables, columns, DAGs, dependencies, queries, tests, and dashboards. It also needs to include the semantic structure of the system, such as grain, measures, dimensions, business definitions, ownership, usage patterns, and the relationships between business concepts.
Most importantly, it needs to persist over time. Persistence changes the agent’s behavior because the agent no longer has to rediscover the stack from scratch for every task. Instead, it can start with an operating model of the system, retrieve the right slice of context for the task, reason about impact, cite evidence, distinguish likely explanations from unlikely ones, and generate safer change plans.
For example, a generic agent with MCP access might inspect a dbt model and propose a SQL edit. A context-aware data agent should also understand what downstream models depend on that change, which dashboards consume those outputs, whether the change affects grain, whether any important metrics depend on the modified columns, whether similar changes have broken tests before, which owners should review the change, and what validation queries should be run before merge.
That is the level of context required for production data work.
The future is MCPs plus context
The point of this post is not that MCPs are wrong or insufficiently useful. The point is that MCPs and context layers solve different parts of the problem.
MCPs make enterprise systems accessible to agents. Context layers make those systems understandable to agents.
Without MCPs, agents are trapped in chat interfaces and cannot do much useful work. Without context, agents are trapped in shallow tool use and have to rediscover the same system state over and over again.
The next generation of enterprise AI systems will be defined by how well they understand the environment they are operating in, and not just defined only by which tools they can call.
For data teams, that means understanding lineage, business logic, metrics, dependencies, ownership, usage, runtime behavior, and change history across the full stack.
That is what turns an agent from a clever assistant into a reliable teammate.
At Typedef, this is why we are building around a simple belief: agents do not just need more tools. They need durable, rich context.
If this is even slightly interesting, please feel free to reach out. We love geeking out about this!