The model is becoming the swappable part.
The ontology is what compounds.
That, to me, is the important idea behind Databricks’ Genie Ontology. The persistent state that gets smarter with every query, every certified metric, every dashboard, every lineage edge, every business definition, and every correction from a human is the actual moat.
This is why Ali Ghodsi calling the Genie Ontology the “secret sauce” matters.
It signals that the industry is moving into a new phase. For the last couple of years, a lot of the conversation around AI products has been about models: which model is better, which model is cheaper, which model has the larger context window, which model is better at reasoning, coding, retrieval, or tool use.
That still matters, but I think the center of gravity is shifting.
For enterprise AI, the durable value will not live only in the model. It will live in the governed context layer around the model.
And that is why ontologies, which for years were treated as important but somewhat niche, are about to become much more central to how companies think about AI systems.
So, what is the Genie Ontology, and why is it interesting?
Based on what Databricks has shared so far, and what I managed to learn during the Databricks conference, here is my current mental model.
What is Databricks Genie Ontology?
The simplest way to think about Genie Ontology is this:
Humans define the canonical business meaning.
Machines learn how that meaning shows up across the company.
Humans correct the machine when it drifts.
The system gets better over time.
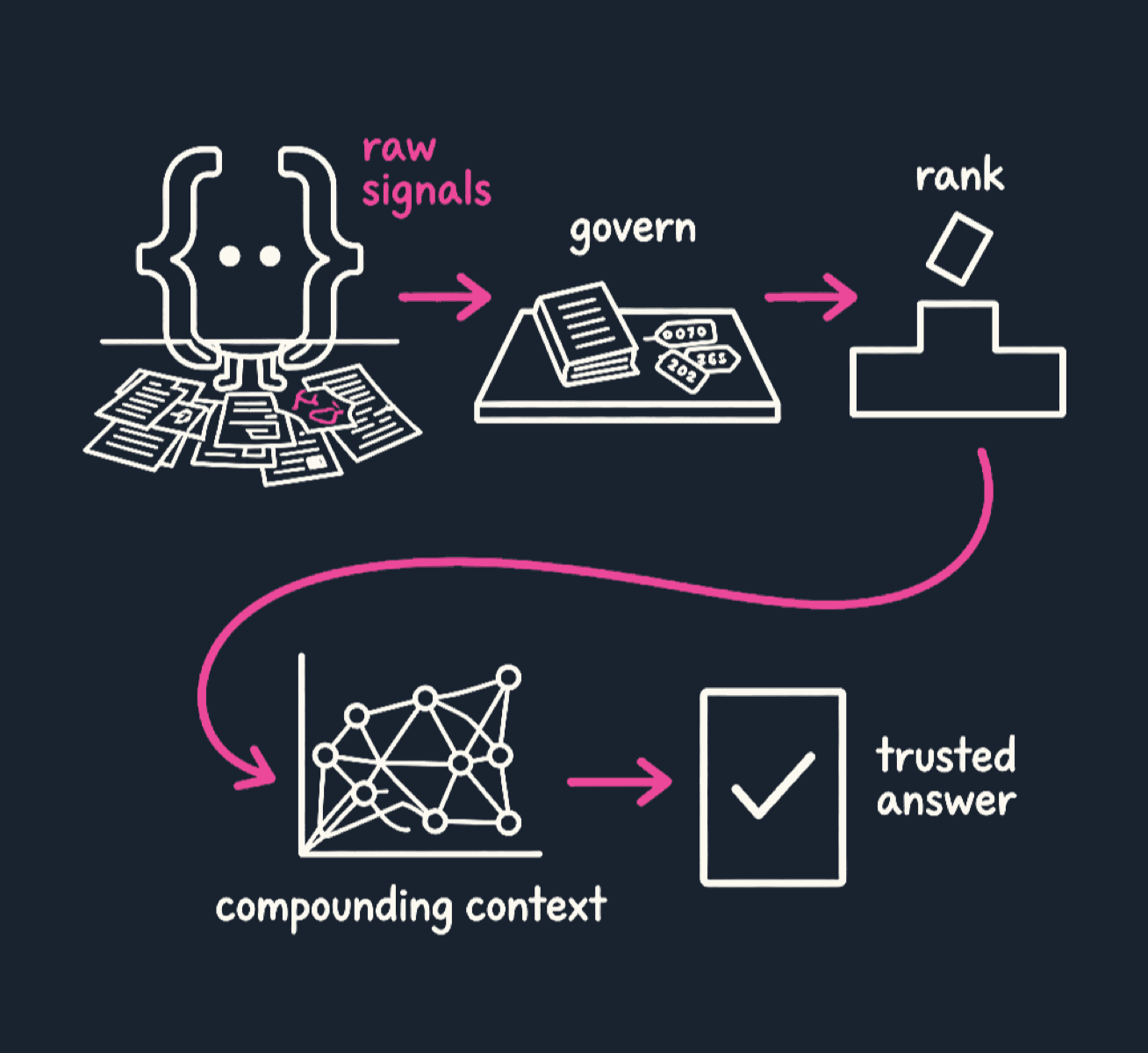
My current mental model is that there are two interacting layers.
The first layer is the governed semantic foundation.
The second layer is the machine-learned ontology that continuously builds enterprise context on top of that foundation.
Layer 1: The governed semantic foundation
The first layer is human-defined and curated.
This is the part that lives in and around Unity Catalog. It includes things like business glossaries, domains, and metrics.
The business glossary defines authoritative concepts, terms, and taxonomies. In theory, if a company already has some of this work done elsewhere, those definitions can be imported or migrated into the governed layer.
Domains group assets in a way that maps to the business. They create ownership and stewardship boundaries. They also help communicate which assets are trusted, certified, or relevant to a specific part of the organization.
Metrics define reusable business measures like revenue, churn, active users, gross margin, pipeline, or retention. The important part is that these are not just random SQL snippets copied across dashboards. They are governed objects that can be reused consistently by BI tools, agents, notebooks, dashboards, and downstream applications.
This layer matters because AI cannot answer business questions reliably if the business itself has not defined what the words mean.
If “revenue” means one thing to finance, another thing to sales, and a third thing to the product analytics team, the model is not going to magically fix that. At best, it will pick one definition. At worst, it will confidently mix them together.
So the governed layer provides the canonical starting point.
But that is not enough.
Because the official definition of the business is only one part of the story. The other part is how the business actually operates.
That is where the machine-learned layer comes in.
Layer 2: The machine-learned enterprise context graph
The Genie Ontology appears to use the governed semantic foundation as input into a broader, continuously learned enterprise context layer.
This is the part that tries to understand how the company actually works by looking across tables, queries, dashboards, pipelines, documents, connected applications, and workplace tools.
In other words, it is not just looking at schema, it is also looking at usage and that distinction is important.
A schema can tell you that a table has a column called customer_id.
It cannot tell you whether that column is trusted, whether the table is deprecated, whether analysts actually use it, whether executives rely on a dashboard built from it, whether another team has a better version, or whether the metric calculated from it is the one the business actually considers authoritative.
To know that, you need more than metadata, you need context.
That context comes from many places: lineage, query history, dashboards, pipelines, documents, certifications, permissions, domains, connected apps, and the way people actually interact with the data.
This is where Databricks is making a very interesting bet.
The system is not just retrieving data at query time. It is building a persistent representation of the enterprise in the background.
A living graph of business meaning.
The hard problem is authority
The hard problem in enterprise analytics is usually not that there is no answer.
The hard problem is that there are too many possible answers.
There are multiple revenue definitions. Multiple customer tables. Multiple churn calculations. Multiple dashboards that appear to answer the same question. Multiple teams using similar words in slightly different ways.
So the core problem becomes:
Which definition deserves to win?
This is where OntoRank becomes the most interesting part of the system.
Databricks describes OntoRank as similar to PageRank. Instead of ranking web pages, it ranks business definitions and relationships.
When multiple definitions of the same concept exist, OntoRank appears to weigh signals like:
- Where the definition came from.
- Who authored it.
- How widely it is used.
- How closely it connects to certified and widely used assets.
- How recently it was updated.
A simple way to think about it is:
OntoRank is PageRank over business meaning, where certified, popular, fresh, well-connected, and authored-by-the-right-person definitions win.
That is a very elegant idea.
If it works, Databricks has a scalable way to resolve enterprise semantic ambiguity without requiring humans to manually curate every possible definition, relationship, and edge case.
If it does not work, Genie Ontology risks becoming another noisy metadata graph with a much better interface.
That is why I think OntoRank is the highest-leverage technical bet inside Genie Ontology.
The success of the system will not depend only on OntoRank, of course. It will also depend on governance adoption, connector coverage, lineage quality, human review workflows, metric-layer quality, permissions, and whether enough of the company’s activity is visible to the system.
But OntoRank feels like the center of gravity.
Because the real question is not whether Databricks can collect a lot of metadata.
The question is whether it can rank meaning.
Query history is behavior, not truth
One part of this that I find especially interesting is the role of usage signals.
From what Databricks has shared, query history is an important signal. Column popularity, for example, can be derived from how often historical queries read from a column.
That means the system is going a step further and is asking what do people actually use?
This makes sense. In a large company, usage is a valuable signal. If many important dashboards, workflows, and queries depend on a specific table or column, that probably tells you something.
But usage is also dangerous.
Query history is behavior, not truth.
A table can be popular because it is correct. It can also be popular because it is old, convenient, badly documented, or accidentally copied into a hundred dashboards years ago.
A metric can be widely used and still be wrong.
A query can be common and still encode a misunderstanding.
This is where the OntoRank bet becomes subtle.
The bet is not simply that query history is useful.
The bet is that usage history, when combined with governance, lineage, freshness, authorship, certification, and graph structure, can become a trustworthy authority signal.
That is very different from just retrieving old SQL queries and giving them to an agent.
And this is where the comparison with Anthropic is interesting.
The Anthropic tension
A few weeks ago, Anthropic shared how they built their internal analytics context layer. One thing that stood out was that raw query history did not help them very much when used directly. Giving the agent access to a large set of historical queries barely improved accuracy.
Their conclusion seemed to be that query history is too noisy to be treated as a direct source of truth.
But it can still be valuable as raw material.
You can mine it. You can distill it. You can turn recurring patterns into curated reference docs, reusable analysis workflows, and better semantic context.
That makes the contrast with Databricks interesting.
Anthropic seems to be saying:
Raw query history is noisy. Distill it before using it as context.
Databricks seems to be betting:
Usage history can become authority signal if it is embedded inside a governed graph and ranked properly.
Those are not necessarily contradictory positions.
In fact, they may be two versions of the same idea.
The question is not whether query history is useful.
The question is whether you can transform query history into reliable semantic signal.
That is what I want to watch closely with Genie Ontology.
If OntoRank can turn usage exhaust into trustworthy business context, that is a big deal.
If not, the human-governed layer will have to do much more of the work than the product positioning might imply.
Why this is different from RAG
This is also why I think Genie Ontology is best understood as part of a broader shift from RAG to ontology.
RAG systems usually retrieve chunks of text at query time and ask the model to reason from them.
That can work well in many situations. But in enterprise analytics, it often breaks down because the hard problem is not simply finding relevant text.
The hard problem is knowing which definition is authoritative, which data source is trusted, which metric should be used, which permissions apply, and which business context matters.
If a model retrieves three different explanations of “revenue,” it still needs to decide which one to trust.
If it retrieves an outdated dashboard, it may answer confidently with the wrong business logic.
If it retrieves SQL from a historical query, it may reproduce a pattern that was popular but incorrect.
The ontology approach front-loads more of the work.
Instead of assembling context only at query time, the system continuously builds a governed graph in the background. It ranks definitions. It connects metrics to tables. It uses lineage. It respects permissions. It routes the agent toward certified data and governed computation instead of letting it free-associate over scattered fragments.
The agent does not just ask the model to reason over random retrieved text.
The agent can use the ontology to resolve the right business concept, find the right metric, identify the right data assets, and generate SQL against governed data.
That is the shift.
RAG retrieves context while ontology maintains context.
RAG asks, “What relevant chunks can I find right now?” while ontology asks, “What does this business mean, and which meaning should be trusted?”
That is a much more powerful foundation for enterprise AI.
Why I think this matters
I am excited about Genie Ontology because it signals that the industry is entering the real building phase of AI.
We have spent a lot of time proving that LLMs can answer questions, write code, summarize documents, and use tools.
Now the question is:
What infrastructure do we need to turn models into reliable products?
I think governed context is one of the most important pillars.
A model without business context is a general-purpose reasoning engine. Useful, but not enough.
A model with access to governed, current, permission-aware, company-specific context becomes something much more valuable.
It can answer questions the way the business actually thinks. It can use the right definitions. It can respect the right boundaries. It can connect analytics to operations. It can become part of workflows instead of just a chat interface on top of documents.
That is why ontology matters.
And that is why I think Databricks putting this much emphasis on Genie Ontology is important.
It makes the ontology conversation mainstream.
The manual part still matters
That said, there are still important open questions.
The first one is the human part.
Databricks is clearly trying to automate as much of the ontology creation and maintenance as possible. That is the right direction. Purely manual ontology-building has failed many times before because the work is too slow, too political, and too hard to keep fresh.
But there is still a governed foundation that humans need to define, curate, approve, or import.
That work does not disappear.
For companies with mature data governance practices, this may be manageable. If they already have business glossaries, certified metrics, domains, ownership models, and stewardship workflows, then Genie Ontology may be able to build on top of what already exists.
But many companies are not there.
For them, the question is:
How much work is required before the automated layer becomes useful?
This is not a small question.
If the governed foundation is weak, the machine-learned layer may learn from noise.
If the official definitions are incomplete, the system has to infer more.
If ownership is unclear, human-in-the-loop curation becomes harder.
If teams disagree about metrics, the ontology may surface the disagreement, but it cannot magically resolve the politics.
So I am very interested to see what the actual bootstrapping experience looks like.
How much can be imported? How much can be inferred? How much needs to be manually approved? How quickly does the system become useful? How much ongoing governance work is required to keep it useful?
That will matter a lot.
The governance angle is a big deal
One thing I do really like about the Databricks approach is that governance is not treated as an afterthought.
In enterprise AI, governance cannot be bolted on at the end.
If an agent is answering questions from company data, it needs to respect permissions. It needs to know which data a user can see. It needs to know which tools it can call. It needs to avoid leaking information through summaries, generated SQL, or retrieved context.
The promise of building this on top of Unity Catalog is that permissions, lineage, certification, ownership, and access control are part of the foundation.
For many enterprises, this may be the biggest reason to take the Databricks approach seriously.
Not because the ontology idea is interesting in the abstract, but because a governed ontology inside the data platform may be much easier to trust than a separate AI layer that has to reconstruct permissions from the outside.
But this also leads to the biggest strategic question.
If context is the moat, whose moat is it?
Databricks is right that the model is not the moat. The context is.
But we need to be very clear about whose moat we are talking about.
For the business, the context layer is incredibly valuable because it is a digital representation of how the company works.
It contains the business definitions, the operating logic, the trusted metrics, the relationships between systems, the way teams think about customers, products, revenue, risk, operations, and growth.
In a very real sense, it encodes what makes the company unique.
You absolutely want to build this context layer.
You want it because it allows AI systems to operate on the actual logic of your business, not just generic knowledge from the internet.
You want it because it can help scale decision-making.
You want it because it can make analytics, operations, support, finance, product, and go-to-market workflows smarter.
But Databricks also wants to be the platform where this context lives. And that is understandable.
What bigger lock-in factor is there than becoming the brain and nervous system of the enterprise?
To be fair, this is not simply a story of closed vendor lock-in. Databricks is making moves around open semantics, federation, connectors, APIs, and interoperability. That matters, and it should not be ignored.
But even if the definitions are portable, the continuously learned context graph may not be and that is the key distinction.
The static semantic definitions may be exportable. The compounding context may still accrue inside the platform.
The lineage graph, usage telemetry, governance workflows, agent behavior, query patterns, materializations, permissions, integrations, and feedback loops may become more valuable the more deeply you live inside the Databricks ecosystem.
That creates a powerful flywheel.
The more of your business you connect to Databricks, the better the ontology becomes.
The better the ontology becomes, the more valuable Databricks becomes.
The more valuable Databricks becomes, the more incentive you have to move additional systems, workflows, and teams into Databricks.
That is great for Databricks.
The question is whether it is always great for you as the customer.
The context layer should be neutral infrastructure
My take is that companies should be very careful here.
The enterprise context layer is too important to be treated as just a feature inside one platform.
It should be sound, it should be complete and it should be interoperable.
By sound, I mean governed, versioned, permission-aware, auditable, and tied to real ownership. The system needs to know which definitions are certified, who owns them, how they changed, and where they are used.
By complete, I mean it needs to represent the business across systems, not just inside the analytics stack. Your business context does not live only in the warehouse. It also lives in product systems, logistics systems, CRM, support tools, documents, Slack threads, workflows, planning tools, and operational applications.
By interoperable, I mean every system that needs to reason about the business should be able to consume that context: Databricks, Snowflake, BI tools, agents, internal apps, workflow engines, customer-facing products, and whatever comes next.
This is where vendor incentives become tricky.
Every major platform wants to be the home for your context layer. Databricks, Snowflake, Salesforce, Microsoft and even the customer support and ticketing system vendors you are using, will try to claim it.
Every system of record and every AI platform will have an incentive to make its own environment the place where your business meaning compounds.
But your business does not fit cleanly inside one vendor’s walls.
Even mature organizations that standardize heavily on one platform usually still use many others. They do that because different teams need different tools, because some systems are better for specific workloads, because migrations take years, and because optionality matters.
You should migrate when a platform is clearly the right place for a workload.
You should not be forced to migrate just because that is the only way your AI context layer can remain complete.
That is the real concern. Not that Databricks is doing something wrong by building Genie Ontology. I think they are doing something very important.
The concern is that the most valuable representation of your business should not become trapped inside one vendor’s runtime.
The real AI moat is sound and complete context
Ali was right that context is the moat.
But for context to be useful, it needs to be both sound and complete.
If it is sound but incomplete, agents will reason correctly over only part of the business.
If it is complete but not sound, agents will have access to everything but will not know what to trust.
You need both.
That is hard because every vendor is naturally incentivized to make context complete inside its own platform. But companies need context that is complete across the business.
This distinction is going to matter more as AI moves from answering analytics questions to executing workflows.
Agentic analytics is only the beginning.
The bigger opportunity is connecting analytics, operations, product, finance, go-to-market, logistics, and customer workflows into systems that can reason and act with business context.
The moment you need to bridge your analytics infrastructure with your product infrastructure, or your logistics systems, or your customer-facing workflows, a platform-specific context layer can become a wall.
The only way to unlock the full value of AI is to curate a sound and complete representation of the business and make it consumable by every system that needs it.
This is what we are building at Typedef
This is exactly the problem we are working on at Typedef.
We believe companies need a neutral context layer for AI.
One that lets them define, govern, and maintain the meaning of their business in a way that is portable across platforms.
One that can be consumed by agents, applications, workflows, data platforms, and operational systems.
One that does not require companies to choose between using the best tools for each job and having a complete representation of their business.
Databricks’ Genie Ontology is exciting because it validates the direction.
It shows that the industry is waking up to the fact that models are not enough.
The next major layer of enterprise AI is the context layer.
The model is swappable and the ontology compounds.
The only question is whether that compounding context becomes a vendor moat or your business moat.
If you are thinking about how to build that business moat in a way that stays governed, complete, and interoperable, I would love to show you what we are building at Typedef.